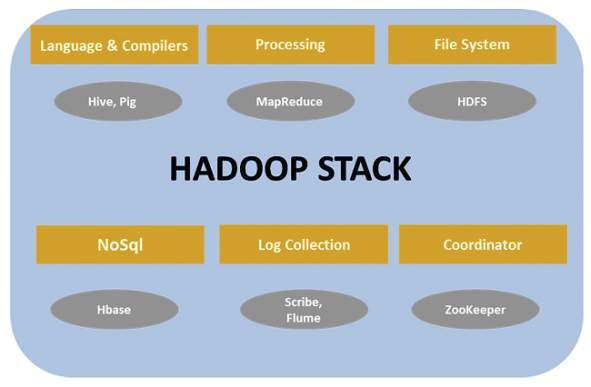
The components of Hadoop Ecosystem are –
Hadoop Distributed File System (HDFS) –
Filesystems that manage the storage across a network of machines are called distributed filesystems.
Hadoop distributed file system (HDFS) is a java based file system that provides scalable and reliable data storage and provides high performance access to data across hadoop cluster.
HDFS is designed for storing very large files with write-once-ready-many-times patterns, running on clusters of commodity hardware. HDFS is not a good fit for low-latency data access, when there are lots of small files and for modifications at arbitrary offsets in the file.
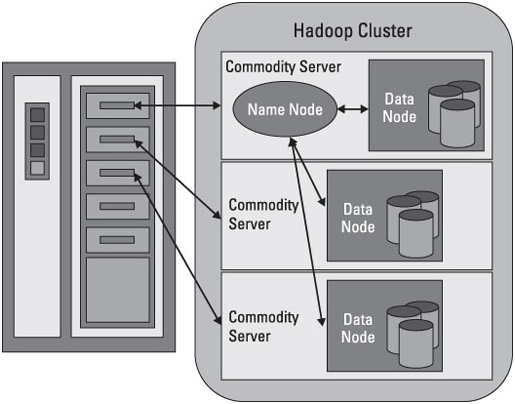
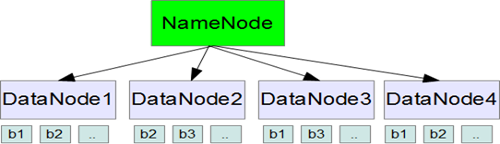
Hadoop employs master slave architecture, with each cluster consisting of a single NameNode that is the master and the multiple DataNodes are the slaves.
The NameNode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files and directories in the tree. The NameNode also knows the DataNodes on which all the blocks for a given file are located. DataNodes are the workhorses of the filesystem. They store and retrieve blocks when they are told to (by clients or the NameNode), and they report back to the NameNode periodically with lists of blocks that they are storing.
Files in HDFS are broken into block-sized chunks, default size being 64MB, which are stored as independent units, and each block of file is independently replicated at multiple data node.
MapReduce –
MapReduce is a simple programming model for processing massive amounts of structured and unstructured data in parallel across a cluster of thousands of machines, in a reliable and fault-tolerant manner. It is the tool that actually gets the data processed.
MapReduce works breaking the processing into two phases –
- Map – The purpose of the map phase is to organize the data in preparation for the processing done in the reduce phase.
- Reduce – Each reduce function processes the intermediate values for a particular key generated by the map function and generates the output.
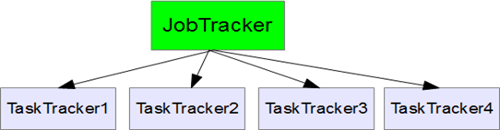
Job Tracker acts as Master and Task Tracker acts as Slave.
A MapReduce job splits a large data set into independent chunks and organizes them into key, value pairs for parallel processing. This parallel processing improves the speed and reliability of the cluster, returning solutions more quickly and with more reliability.
The Map function divides the input into ranges by the InputFormat and creates a map task for each range in the input. The JobTracker distributes those tasks to the worker nodes. The output of each map task is partitioned into a group of key-value pairs for each Reduce.
The Reduce function then collects the various results and combines them to answer the larger problem the master node was trying to solve. Each reduce pulls the relevant partition from the machines where the maps executed, then writes its output back into HDFS. Thus, the reduce is able to collect the data from all of the maps for the keys it is responsible for and combine them to solve the problem.
Hive –
Apache Hive is an open-source data warehouse system for querying and analysis of large, stored in Hadoop files data sets. Hive has three main functions: data summary, queries and analyzers.
It provides an SQL-like language called HiveQL while maintaining full support for map/reduce. In short, a Hive query is converted to MapReduce tasks. The main building blocks of Hive are – Metastore stores the system catalog and metadata about tables, columns, partitions, etc. Driver manages the lifecycle of a HiveQL statement as it moves through Hive Query Compiler compiles HiveQL into a directed acyclic graph for MapReduce tasks Execution Engine executes the tasks produced by the compiler in proper dependency order Hive Server provides a Thrift interface and a JDBC / ODBC server.
In addition HiveQL supported in queries embedding individual MapReduce scripts. Hive also allows serialization / deserialization of data.
Hive supports text files (including flat files called), SequenceFiles (flat- Files consisting of binary key / value pairs) and RCFiles (Record Columnar files which store the columns of a table in the manner of a column-based database).
PIG –
Apache Pig is an open-source technology that offers a high-level mechanism for the parallel programming of MapReduce jobs to be executed on Hadoop clusters.
Pig enables developers to create query execution routines for analyzing large, distributed data sets without having to do low-level work in MapReduce, much like the way the Apache Hive data warehouse software provides a SQL-like interface for Hadoop that doesn’t require direct MapReduce programming.
The key parts of Pig are a compiler and a scripting language known as Pig Latin. Pig Latin is a data-flow language geared toward parallel processing. Through the use of user-defined functions (UDFs), Pig Latin applications can be extended to include custom processing tasks written in Java as well as languages such as JavaScript and Python.
Pig is intended to handle all kinds of data, including structured and unstructured information and relational and nested data.
HBase –
Apache HBase is a column-oriented key/value data store built to run on top of the Hadoop Distributed File System (HDFS). Hadoop is a framework for handling large datasets in a distributed computing environment.
HBase is designed to support high table-update rates and to scale out horizontally in distributed compute clusters. Its focus on scale enables it to support very large database tables — for example, ones containing billions of rows and millions of columns. Currently, one of the most prominent uses of HBase is as a structured data handler for Facebook’s basic messaging infrastructure.
HBase is known for providing strong data consistency on reads and writes, which distinguishes it from other NoSQL databases. Much like Hadoop, an important aspect of the HBase architecture is the use of master nodes to manage region servers that distribute and process parts of data tables.
ZooKeeper –
Apache ZooKeeper is an open source file application program interface (API) that allows distributed processes in large systems to synchronize with each other so that all clients making requests receive consistent data.
The Zookeeper service is provided by a cluster of servers to avoid a single point of failure. Zookeeper uses a distributed consensus protocol to determine which node in the ZooKeeper service is the leader at any given time.
The leader assigns a timestamp to each update to keep order. Once a majority of nodes have acknowledged receipt of a time-stamped update, the leader can declare a quorum, which means that any data contained in the update can be coordinated with elements of the data store. The use of a quorum ensures that the service always returns consistent answers.
Sqoop –
Sqoop allows easy import and export of data from structured data stores such as relational databases, enterprise data warehouses, and NoSQL systems. The dataset being transferred is sliced up into different partitions and a map-only job is launched with individual mappers responsible for transferring a slice of this dataset.
Flume –
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into the Hadoop Distributed File System (HDFS). It has a simple and flexible architecture based on streaming data flows; and is robust and fault tolerant with tunable reliability mechanisms for fail-over and recovery.
In Flume, the entities you work with are called sources, decorators, and sinks. A source can be any data source, and Flume has many predefined source adapters. A sink is the target of a specific operation (and in Flume, among other paradigms that use this term, the sink of one operation can be the source for the next downstream operation). A decorator is an operation on the stream that can transform the stream in some manner, which could be to compress or decompress data, modify data by adding or removing pieces of information, and more.
Oozie –
Oozie is a workflow processing system that lets users define a series of jobs written in multiple languages – such as Map Reduce, Pig and Hive – then intelligently link them to one another. Oozie allows users to specify, for example, that a particular query is only to be initiated after specified previous jobs on which it relies for data are completed.
Mahout –
Mahout is an open source machine learning library from Apache. It’s highly scalable. Mahout aims to be the machine learning tool of choice when the collection of data to be processed is very large, perhaps far too large for a single machine. At the moment, it primarily implements recommender engines (collaborative filtering), clustering, and classification. Recommender engines try to infer tastes and preferences and identify unknown items that are of interest. Clustering attempts to group a large number of things together that share some similarity. It’s a way to discover hierarchy and order in a large or hard-to-understand data set. Classification decides how much a thing is or isn’t part of some type or category, or how much it does or doesn’t have some attribute.